https://discord.com/channels/1124331179580084406/1124334001507794994/1255004192993443910
ちょうどいい(?)ネタがあったので、これを例に作ってみます。
既にどこかに存在するのかどうか?は知りません。 (大抵、よほど複雑でなければ数分で書けるので、探すより書いた方が速いので、大体調べずに雑に書くことが多い)
とりあえず、いつも自分がやってる手順をざっくり説明します。
最終的な手順は以下のgithubのコミットを参照
https://github.com/xuwei-k/scalafix-rules/compare/xuwei-k:be79a66...xuwei-k:a800986
手順1: 例となるコードから雛形生成
自作のscala-jsで作ったサイトを利用。
パラメーターはなんか画像の通りです。 ここの細かい設定の説明は省略。
かなり細かく設定できて、出来るだけ雛形そのまま使えるように色々パラメーターがあります。
今回の例はSemanticRuleではなくてSyntacticRuleでいいな!という判断ができる知識がこの時点で必要ですが・・・
https://xuwei-k.github.io/scalameta-ast/
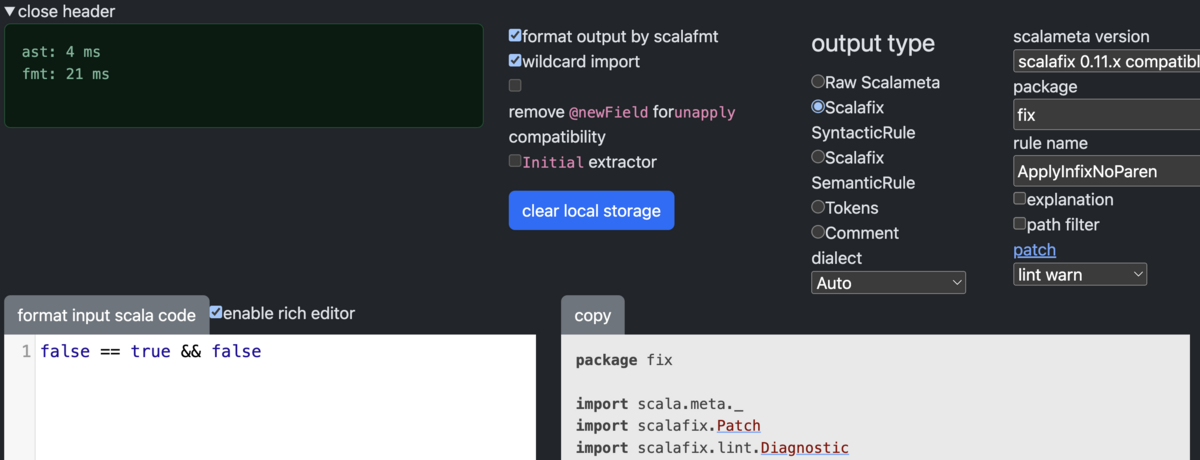
手順2: それをとりあえず貼り付け
https://github.com/xuwei-k/scalafix-rules/commit/f48ea0f921f90811749e0992e2b90535baf0b040
package fix import scala.meta._ import scalafix.Patch import scalafix.lint.Diagnostic import scalafix.lint.LintSeverity import scalafix.v1.SyntacticDocument import scalafix.v1.SyntacticRule import scalafix.v1.XtensionSeqPatch class ApplyInfixNoParen extends SyntacticRule("ApplyInfixNoParen") { override def fix(implicit doc: SyntacticDocument): Patch = { doc.tree.collect { case t @ Term.ApplyInfix.After_4_6_0( Term.ApplyInfix.After_4_6_0( Lit.Boolean(false), Term.Name("=="), Type.ArgClause(Nil), Term.ArgClause(List(Lit.Boolean(true)), None) ), Term.Name("&&"), Type.ArgClause(Nil), Term.ArgClause(List(Lit.Boolean(false)), None) ) => Patch.lint( Diagnostic( id = "", message = "", position = t.pos, severity = LintSeverity.Warning ) ) }.asPatch } }
手順3: 構造をそのまま利用する部分と、具体的な値を無視する部分を判断して、一部をワイルドカードに書き換え
https://github.com/xuwei-k/scalafix-rules/commit/a7defcf4f2e861a1419617c1c9337f0db4c4d3a8
今回の場合は、とにかく中置記法、scalametaのTreeでいうと ApplyInfix がネストしてるものだけ雑に検知してみるので、こう
doc.tree.collect {
case t @ Term.ApplyInfix.After_4_6_0(
- Term.ApplyInfix.After_4_6_0(
- Lit.Boolean(false),
- Term.Name("=="),
- Type.ArgClause(Nil),
- Term.ArgClause(List(Lit.Boolean(true)), None)
- ),
- Term.Name("&&"),
- Type.ArgClause(Nil),
- Term.ArgClause(List(Lit.Boolean(false)), None)
+ _: Term.ApplyInfix,
+ _,
+ _,
+ _
) =>
手順4: 括弧を含んでない、という条件を表現する
「 括弧を含んでない、という条件」をどうするか?という観点ですが、正確に位置を判断しようとすると、まぁまぁ難しいです。 本当にちょうどApplyinfixの部分に対するカッコの判断なのか?が難しいので。つまり
aaa && bbb.f(ccc) == xxx
だと、括弧は含んでいるが、infixそのものに対しては括弧つけてません。
さて、コード上で括弧含むか?は、Treeには直接現れません。これはtokenレベルで判断する必要があります。
(さらにすごく雑にやるならコードをStringとして処理してもいいが、それよりはtokenレベルの方がマシというか正攻法)
こんな時のために?自作のサイトはtoken表示機能もあります。
つまり、以下のようになります。
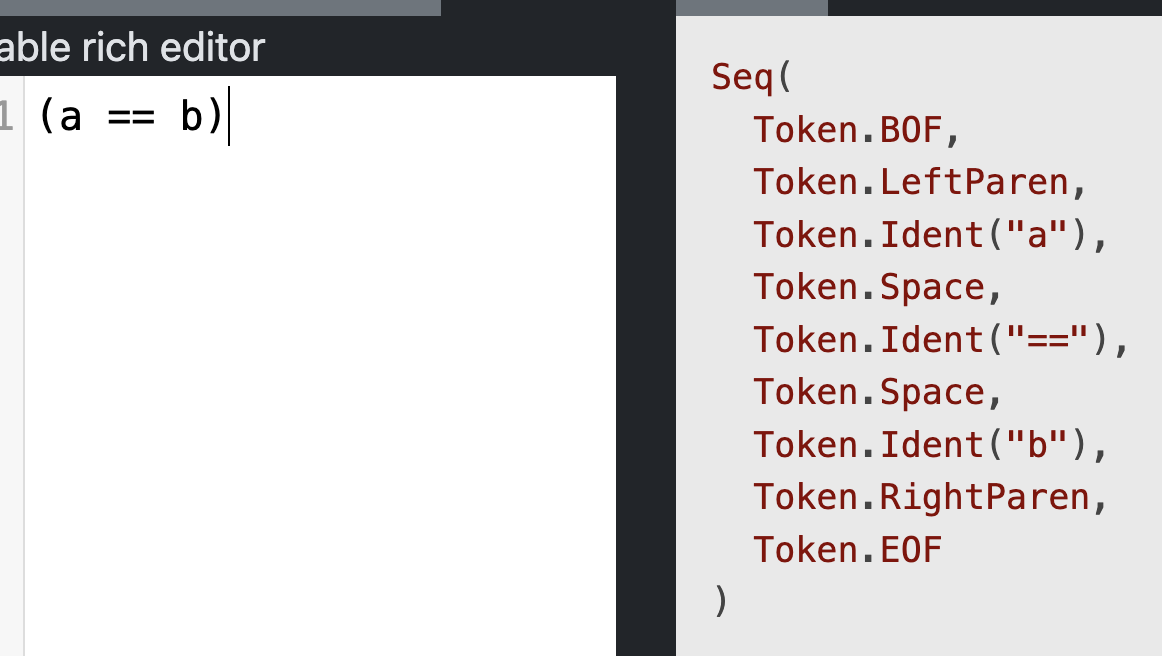
( が LeftParen で ) が RightParen ということがわかりました。
今回はサボって、それが含んでいればとりあえずヨシ!という雑条件にすると、つまりこう
_ - ) => + ) if t.tokens.forall(!_.is[Token.LeftParen]) => Patch.lint(
手順5: メッセージ変更
ここは日本語でも英語でも好きに書いてください。 場合によって、警告出す位置を調整するためにposやその他を変更する場合もありますが、今回はそのままで。 あと、warningにしてますが、errorにしたり、そこも好きに変えましょう。
id = "", - message = "", + message = "中置記法を複数連続して書く場合は、必ず括弧を使って優先順位を明確にしてください", position = t.pos,
手順6: テスト書く
この手順はTDDでやるなら先にやるべきです。個人的には、最終的に完成すれば手順はこだわらないのでどっちでいいかぁ、という気持ちですね。
既にprojectの構成ができていれば、以下のようなファイルを書いて、scalafixのtestkitが認識する特別なassertコメントを書いて、テストが通れば完了です。
テストするruleも、以下のように特別なコメントとして上の方に書く決まりになっています。
/* rule = ApplyInfixNoParen */ package fix trait ApplyInfixNoParenTest { def f1: Boolean = false == true && false // assert: ApplyInfixNoParen def f2: Boolean = (false == true) && false // これはOK def f3: Boolean = false == (true && false) // これもOK }
いかがでしたか!?!?!?!?
scalafix書き慣れているので、この程度なら全く詰まらずに書けますが、本来は詰まった時のdebug方法が一番重要だったりしますが、その説明は面倒なので、今回は行いません。
また、今回はtokenに変換しての検査が出てきましたが、tokenレベルでの処理が必要なことはあまり多くないです。若干珍しいパターンでしたね。
途中で解説しましたが、これはカッコの位置を正確に考慮してないので、改善の余地がありますが、それは読者への宿題とします(?)
あとは、infixは文字の種別によって優先順位が決まって、型を見る必要がないはず?なので、警告するパターンではなく、現状の優先順位に従って括弧をひたすら付与する書き換えのruleを作ってみるのもいいですね?それも宿題とします、頑張ってください!